MLflow is a popular open-source tool that plays a key role in implementing MLOps, which stands for Machine Learning Operations. MLOps is essentially the application of DevOps practices to the machine learning lifecycle. In simpler terms, it’s about streamlining the process of developing, deploying, and managing machine learning models.
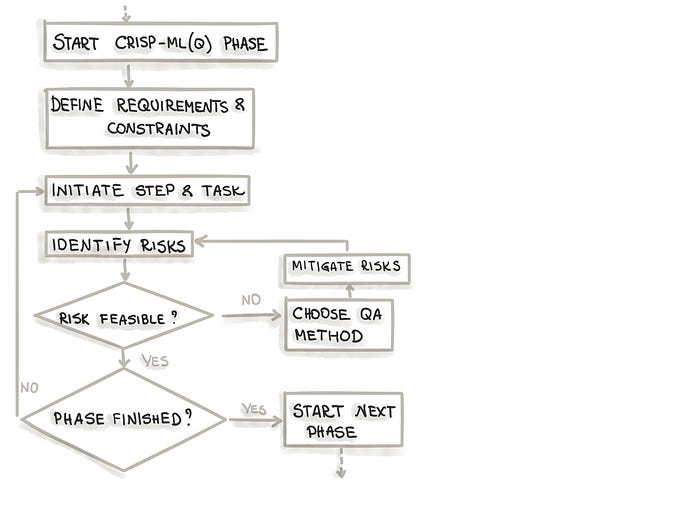
The machine learning community is currently working towards establishing a standardized process model for the development of machine learning projects. Consequently, many projects in the realms of machine learning and data science lack proper organization, leading to challenges in reproducibility of results. Typically, these projects are conducted in an ad-hoc manner. In order to provide guidance to machine learning practitioners throughout the development lifecycle, a recent proposal introduced the Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology (CRISP-ML(Q)). In this review, we delve into the fundamental phases of the machine learning development process model. While there exists a specific sequence for the individual stages, it’s essential to acknowledge that machine learning workflows are inherently iterative and exploratory. Therefore, based on outcomes from subsequent phases, there might be a need to revisit earlier steps.

Overall, the CRISP-ML(Q) process model describes six phases:
- Business Understanding and Data Understanding: This initial phase combines understanding the business problem and the available data. You’ll define the business objectives, identify success metrics, and explore the data to understand its characteristics and potential for machine learning.
- Data Preparation: Similar to the traditional lifecycle, this stage focuses on cleaning and preparing the data for modeling. This includes handling missing values, dealing with inconsistencies, and potentially transforming the data into a suitable format.
- Modeling and Tuning: Here, you select and experiment with different machine learning algorithms. You’ll train models on the prepared data and use techniques like hyperparameter tuning to optimize their performance.
- Evaluation: This phase is crucial for assessing the effectiveness of the trained models. You’ll use various evaluation metrics to judge the model’s performance on unseen data and compare different models to select the best one.
- Deployment: If a model performs well, it’s time to deploy it into production. This involves packaging the model, integrating it with your system, and setting up infrastructure to serve predictions.
- Monitoring and Maintenance: Just like in the traditional lifecycle, monitoring the model’s performance over time is essential. You’ll track its accuracy, address any degradation, and retrain the model with new data as needed to maintain its effectiveness.
CRISP-ML offers several advantages:
- Standardization: It provides a common language and framework for machine learning projects, fostering collaboration and knowledge sharing across teams.
- Structured Approach: By following its phases, you ensure a comprehensive and well-organized development process, reducing the risk of overlooking crucial steps.
- Improved Communication: CRISP-ML terminology facilitates communication between data scientists, business stakeholders, and other project members.
While CRISP-ML is not a rigid prescription, it serves as a valuable guideline for developing robust and successful machine learning models.
For every stage outlined in the process model, CRISP-ML(Q) mandates a quality assurance approach that involves several key components. These include defining requirements and constraints, such as performance benchmarks and data quality standards, instantiating specific tasks like selecting machine learning algorithms and conducting model training, identifying potential risks that could hinder the effectiveness and achievement of the machine learning application, such as bias, overfitting, or reproducibility issues, and implementing quality assurance methods to mitigate these risks when necessary. Examples of such methods include employing cross-validation techniques and thoroughly documenting both the process and the results obtained.
Components of MLflow
MLflow is composed of several key components that collectively support the machine learning lifecycle. These components work together to streamline the development, experimentation, deployment, and monitoring of machine learning models. Core components of MLflow:
1. MLflow Tracking:
- Function: Tracks experiments throughout the machine learning lifecycle. It acts as the central hub for recording information about your training runs.
- Key Features:
- Logs parameters used during training (e.g., learning rate, number of epochs).
- Captures metrics to evaluate model performance (e.g., accuracy, loss).
- Tracks artifacts generated during runs (e.g., trained model files, code versions).
- Provides an API and UI for interacting with this logged information.
2. MLflow Projects:
- Function: Ensures reproducibility of your machine learning projects.
- Key Features:
- Packages your code, environment, and dependencies into a reusable structure.
- Enables running the same project on different machines or environments with consistent results.
- Promotes collaboration by sharing projects easily among team members.
3. MLflow Models:
- Function: Simplifies the management of trained machine learning models.
- Key Features:
- Saves models in a platform-agnostic format for flexibility.
- Facilitates version control of models for tracking changes and rollbacks.
- Enables deployment of models across diverse serving environments.
- Streamlines serving predictions from trained models.
4. MLflow Model Registry (Optional):
- Function: Provides a centralized repository for advanced model governance. (Not essential for basic MLflow usage)
- Key Features:
- Stores and manages different versions of your trained models.
- Offers stage transitions for models (e.g., development, staging, production).
- Implements model approval workflows for controlled deployment.
- Enhances governance and accountability in production environments.
Remember, these components can be used independently for specific tasks. However, their true power lies in their synergy. By combining MLflow Tracking, Projects, and Models, you can create a robust and reproducible machine learning workflow that fosters collaboration and success in your ML endeavors.
These components together form a comprehensive platform for managing the end-to-end machine learning lifecycle, from experimentation and development to deployment and monitoring. By using MLflow, data scientists and machine learning engineers can streamline their workflow, increase productivity, and improve collaboration and reproducibility across the entire organization.
MLflow Setup
Setting up MLflow involves several steps, including installation, configuration, and possibly integration with other tools or platforms. Below is a general guide to setting up MLflow:
Install MLflow:
You can install MLflow using Python’s package manager pip. Run the following command in your terminal or command prompt:
pip install virtualenv
python -m venv venv
source venv/bin/activate
pip install mlflowStart MLflow Tracking Server (if using):
- If you installed the MLflow tracking server, you can start it by running the following command in your terminal:
mlflow uiThis command starts the MLflow tracking server locally, and you can access the web UI by navigating to http://localhost:5000 in your web browser.
Clone (download) the MLflow repository via
git clone https://github.com/mlflow/mlflowcd into the examples directory within your clone of MLflow - we’ll use this working directory for running the tutorial. We avoid running directly from our clone of MLflow as doing so would cause the tutorial to use MLflow from source, rather than your PyPI installation of MLflow.
Running the MLFlow Experiment
Before we run our experiment, make sure we set our tracking URI to our MLFlow server to ensure our results are logged. Simply export the environment variable in your terminal:
export MLFLOW_TRACKING_URI=http://localhost:5000
To define the URI for a singular command, use: MLFLOW_TRACKING_URI=http://localhost:5000 mlflow run . --experiment-name=experiment_name_here
Once our server and URI are set, we’re ready to run the experiment! In the directory with our example, run the command: mlflow run . --experiment-name=sklearn_lr_example
If you want to name this specific run, add --run-name name_your_run_here
cd mlflow/examples/sklearn_logistic_regression/
export MLFLOW_TRACKING_URI=http://localhost:5000
# if error Can't Find pyenv
curl https://pyenv.run | bash
python -m pip install virtualenv
PATH="$HOME/.pyenv/bin:$PATH"
mlflow run . --experiment-name=lr_example --run-name=first_run
MLFlow Dashboard and Model Serving
Now that our sample run is finished, we can take a closer look at how to access this experiment via the MLFlow server dashboard.
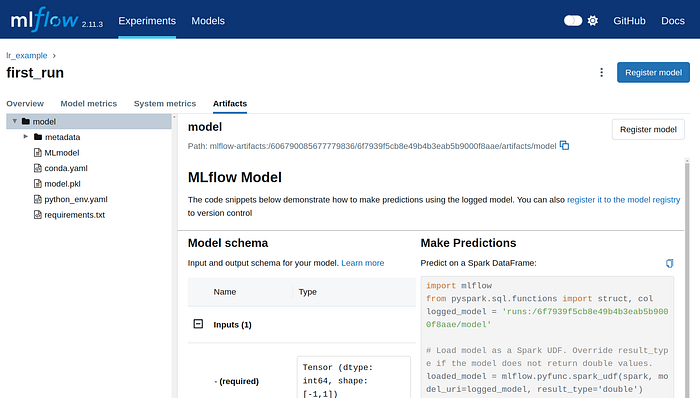
To serve this model:
Copy the “Run ID” or the “Full Path” of the model artifact for the specific run you would like to host.
Now, serve the model by running one of the commands below. This command will host the model on the machine with port 1234. It’s important to indicate the port number as the default port is 5000, which is the default port of our MLFlow server. Feel free to change this port number as needed:
If you used the “Run ID”:
mlflow models serve -m runs:/paste_your_ID_here --port 1234If you used the “Full Path”:
mlflow models serve -m mlflow-artifacts:/.../.../artifacts/model --port 1234
We’re now ready to send a request to test our model. For a quick test, we’ll be using curl to send a DataFrame over to the model:
curl -d '{"dataframe_split": {"columns": ["x"], "data": [[5],[-1],[0],[1],[2],[1]]}}' -H 'Content-Type: application/json' -X POST localhost:1234/invocations
Model Registration & Version Control
One last important MLFlow feature we’ll be discussing is the model registry. Registering models in MLFlow is an essential step in the model management process as it allows for:
- Versioning: When a model is registered, it is given a unique version number. This allows for tracking of changes to the model over time and rollback to previous versions if necessary.
- Tracking: Registered models can be tracked, which means that the model’s performance, input, and output can be logged and visualized in the MLFlow UI. This allows for a better understanding of how the model is performing and how it is being used.
- Deployment: Registered models can be easily deployed to a production environment. MLFlow provides a simple API for deploying models, which makes it easy to integrate models into existing systems.
- Reproducibility: Registered models can be associated with metadata such as model descriptions, authors, and run information, which makes it easy to reproduce experiments and understand the context in which a model was created.
- Collaboration: Registered models can be shared with others, making it easy for other team members to use and improve the model.
For now, let’s register one of our models via our server dashboard:
Going back to one of our runs, you’ll notice a “Register Model” button. Click this to make a new model (or register this run to an existing model).
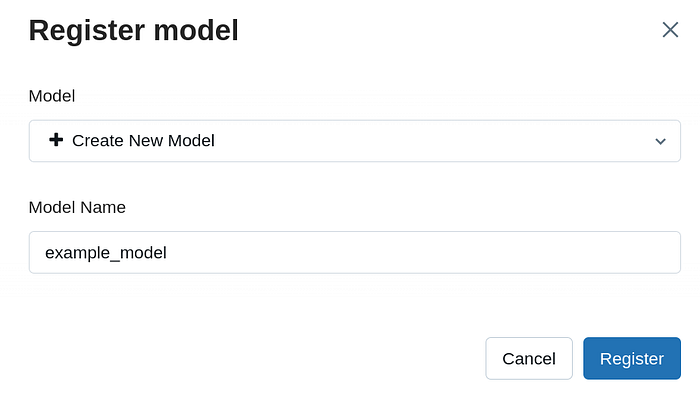
You should see this in your server dashboard’s “Models” section. You’ll see an overview of the latest version, variants in the staging phase, and the current production model. To register a production model, click on the model name.
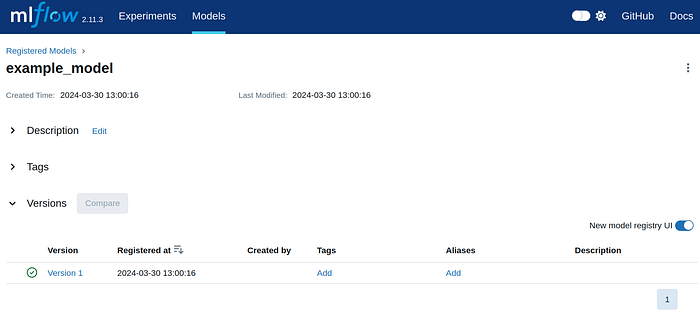
Click on the version you wish to use as your production model.
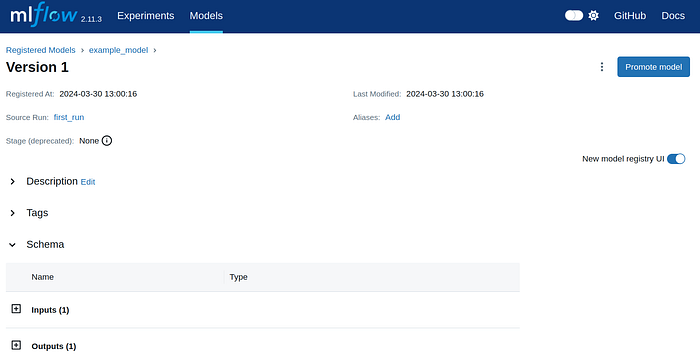
You can now use the same MLFlow command previously used to serve the model. This time, you can reference the model by its name and version:
mlflow models serve -m "models:/example_model/1" –port 1234
For more information refer to MLflow Projects.
If you found this article insightful and want to explore how these technologies can benefit your specific case, don’t hesitate to seek expert advice. Whether you need consultation or hands-on solutions, taking the right approach can make all the difference. You can support the author by clapping below 👏🏻 Thanks for reading!
